

一、KRaft机制介绍
1、KRaft简单介绍
Apache Kafka Raft (KRaft) 是为消除 Apache Kafka 对 ZooKeeper 进行元数据管理的依赖而引入的共识协议。这大大简化了 Kafka 的架构,将元数据的责任合并到 Kafka 本身,而不是将其拆分为两个不同的系统:ZooKeeper 和 Kafka。KRaft 模式在 Kafka 中使用了一个新的仲裁控制器服务,它取代了以前的控制器,并使用了 Raft 共识协议的基于事件的变体。
Apache Kafka在3.0版本中内置的KRaft共识机制取代Zookeeper。该模式在2.8版本当中就已经发布了体验版本,在3.X系列中KRaft是一个稳定release版本。
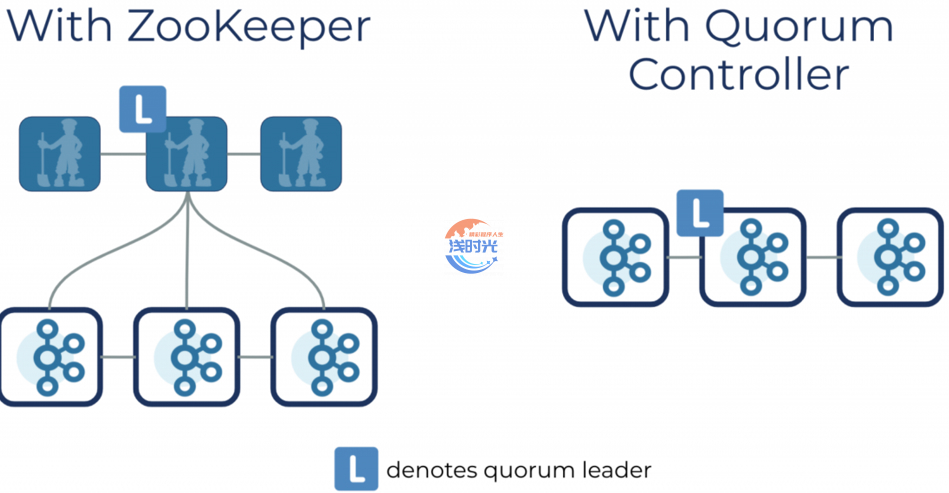
2、Kafka Quorum 控制器的好处
- 通过使用新的元数据管理改进控制平面性能,使 Kafka 集群能够扩展到数百万个分区
- 提高稳定性,简化软件,更容易监控、管理和支持 Kafka。
- 允许 Kafka 为整个系统提供单一的安全模型
- 提供一种轻量级的单进程方式来开始使用 Kafka
- 使控制器故障转移几乎是即时的
3、工作模式
仲裁控制器使用新的 KRaft 协议来确保元数据在仲裁中准确复制。仲裁控制器使用事件源存储模型存储其状态,从而确保始终可以准确地重新创建内部状态机。用于存储此状态的事件日志(也称为元数据主题)会定期通过快照进行删减,以保证日志不会无限增长。仲裁中的其他控制器通过响应活动控制器创建并存储在其日志中的事件来跟随活动控制器。因此,如果一个节点由于分区事件而暂停,例如,它可以通过在重新加入时访问日志来快速赶上它错过的任何事件。这显着减少了不可用窗口,从而缩短了系统的最坏情况恢复时间。
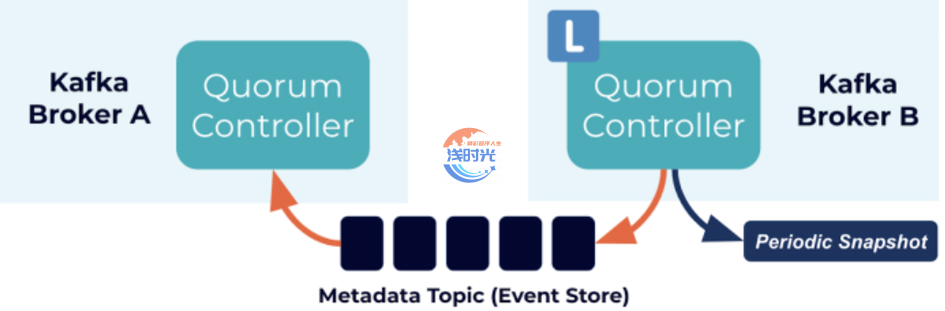
KRaft 协议的事件驱动特性意味着,与基于 ZooKeeper 的控制器不同,仲裁控制器在激活之前不需要从 ZooKeeper 加载状态。当领导层发生变化时,新的活动控制器已经在内存中拥有所有提交的元数据记录。更重要的是,在 KRaft 协议中使用的相同的事件驱动机制用于跨集群跟踪元数据。以前使用 RPC 处理的任务现在受益于事件驱动以及使用实际日志进行通信。
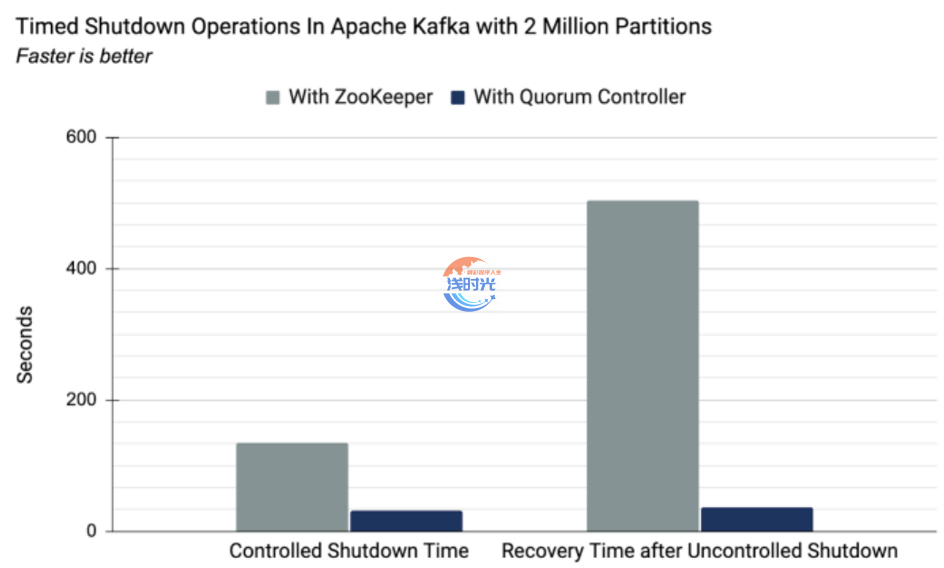
4、与ZK配置对比
| 使用Zookeeper | 使用Kraft | |
| 配置客户端和服务 | zookeeper.connect=zookeeper:2181 | bootstrap.servers=broker:9092 |
| 配置模式注册表 | kafkastore.connection.url=zookeeper:2181 | kafkastore.bootstrap.servers=broker:9092 |
| Kafka管理工具 | kafka-topics –zookeeper zookeeper:2181 | kafka-topics –bootstrap-server broker:9092 … –command-config properties to connect to brokers |
| REST 代理 API | v1 | v2 或 v3 |
| 获取 Kafka 集群 ID | zookeeper-shell zookeeper:2181 get/cluster/id | kafka-metadata-quorum或查看metadata.properties或confluent cluster describe –url http://broker:8090 –output json |
二、kafka集群部署
提示:在kafka-zk01上安装好Kafka后直接拷贝给另外2个节点即可,以下只记录kafka-zk01节点,另外2个节点类似
1、解压安装
[root@kafka-zk01 ~]# cd /opt/soft
[root@kafka-zk01 soft]# tar -zxvf kafka_2.13-3.1.0.gz -C /usr/local/
[root@kafka-zk01 soft]# cd /usr/local/
[root@kafka-zk01 local]# mv kafka_2.13-3.1.0 kafka
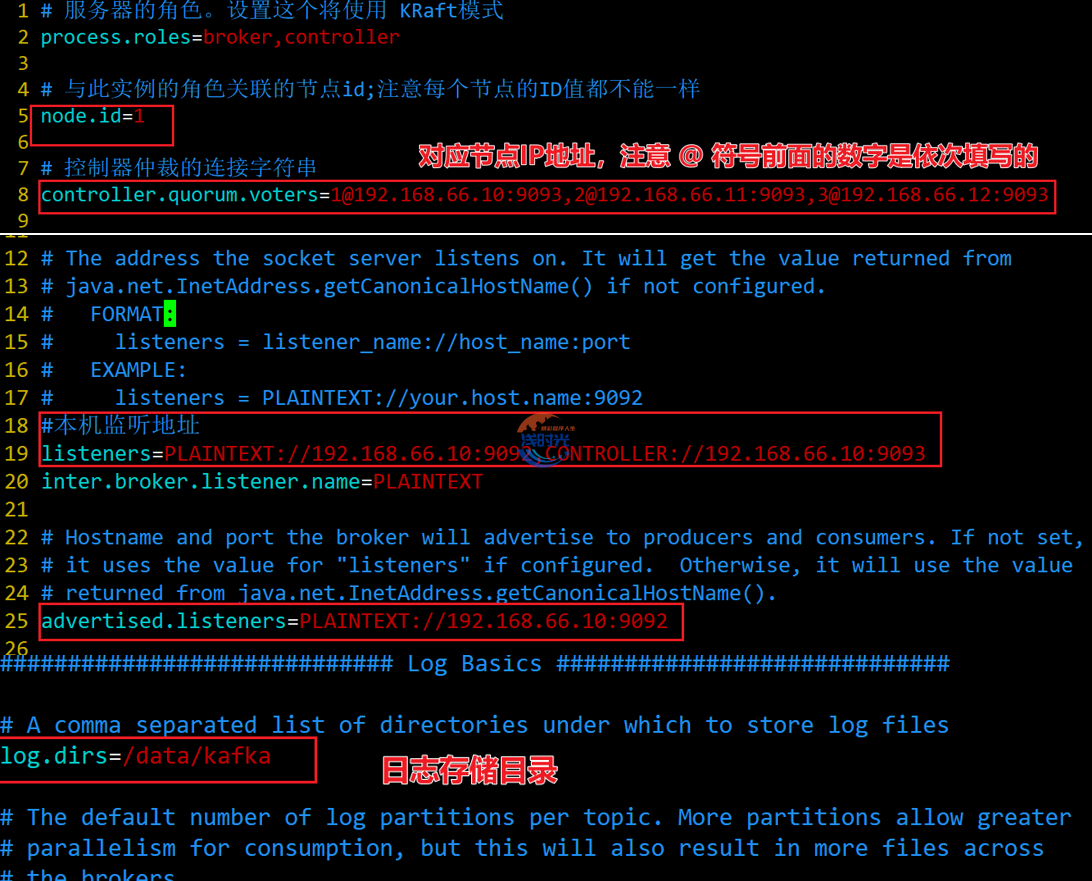
2、修改配置
- 三个节点的配置都需要进行修改,node1上安装好程序后拷贝至另外2个节点,然后登入到另外2台节点服务器进行修改配置文件
- 注意 每台主机的node.id不可以重复,需要根据实际服务器IP进行修改监听地址
- 配置文件路径:
kafka安装目录 /config/kraft/server.properties
3、格式化存储数据目录
[root@kafka-zk01 ~]# cd /usr/local/kafka/bin/
[root@kafka-zk01 bin]# ./kafka-storage.sh random-uuid
3S3eLM1kQ5KP-tYT103bJg
#三台节点都要使用上面生成的唯一集群ID进行格式化数据存储目录
/usr/local/kafka/bin/kafka-storage.sh format -t 3S3eLM1kQ5KP-tYT103bJg -c /usr/local/kafka/config/kraft/server.properties
4、通过Systemd管理服务
cat > /etc/systemd/system/kafka.service << EOF
[Unit]
Description=Apache Kafka server (broker)
Documentation=https://kafka.apache.org
After=network.target
Wants=network-online.target
[Service]
Type=forking
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/kraft/server.properties
Restart=on-failure
LimitNOFILE=265535
[Install]
WantedBy=multi-user.target
EOF
5、三节点依次启动kafka
systemctl daemon-reload
systemctl restart kafka.service
systemctl status kafka.service
systemctl enable kafka.service
6、集群高可用测试
- 自己手动在任一节点创建Topic,然后其他节点查看Topic
- 手动创建生产者Producer,其他节点创建消费者Consumer进行消费
必须 注册 为本站用户, 登录 后才可以发表评论!